
Statistical Learning From Speech
Post by Anastasia Sares
The takeaway
Spontaneous speech synchronizers are those who unconsciously align their own speech production with an external stimulus. People who do this are also better at identifying patterns in artificial babble speech, and it may be because they are using additional brain areas when processing speech in general.
What's the science?
Language learning is a complex and challenging process. When first learning to speak, or when learning a second language, we often hear strings of sounds with no obvious break between them. But through repeated listening, our brains can pick up on patterns, determining which groups of sounds occur together more often—these are more likely to be words. The process is called “statistical learning,” and it can be tested in the lab using artificial speech. Individuals vary in their statistical learning ability. In a recent study, it was discovered that some people spontaneously synchronize their own speech with external speech, and these people are also better at statistical learning.
But why would spontaneous speech synchrony make a person better at statistical learning? This week in PLoS Biology, Orpella, Assaneo and colleagues tried to see whether brain activity during statistical learning could distinguish between spontaneous synchronizers and non-synchronizers and whether this difference in brain activity could account for their enhanced statistical learning ability.
How did they do it?
The authors recruited two groups of people: one to confirm the effect of spontaneous speech synchrony on statistical learning, and another group to perform this task while undergoing magnetic resonance imaging (MRI) to understand the brain regions involved.
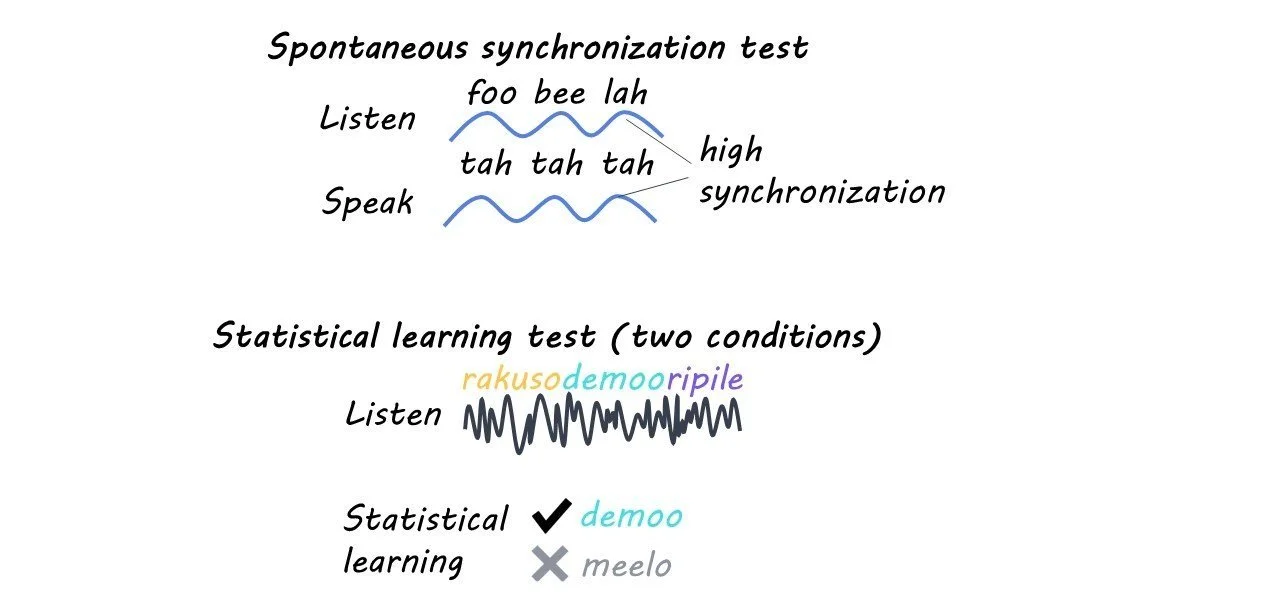
The first measure was spontaneous speech synchrony—participants heard a string of spoken syllables and were instructed to whisper “tah” repeatedly while listening. Synchronizers will align their speech to the syllables they hear, while non-synchronizers will not align their speech, so this task separated the participants into two groups.
In the statistical learning task, participants heard strings of nonstop syllables containing embedded “words” (three syllables that repeatedly occurred together in the same order, like “rakuso”). Afterward, they were tested by being shown two “words” and choosing which one they had heard. There were two conditions in this task—in one, participants listened to the stream of syllables normally, while in the other, they were required to say “tah” repeatedly (this is supposed to interfere with the statistical learning).
The second group of participants completed the statistical learning task while in an MRI, and afterward their brain activity was split up into networks using a technique called Independent Component Analysis (ICA). The networks were tested individually to see which ones had activity related to the task.
What did they find?
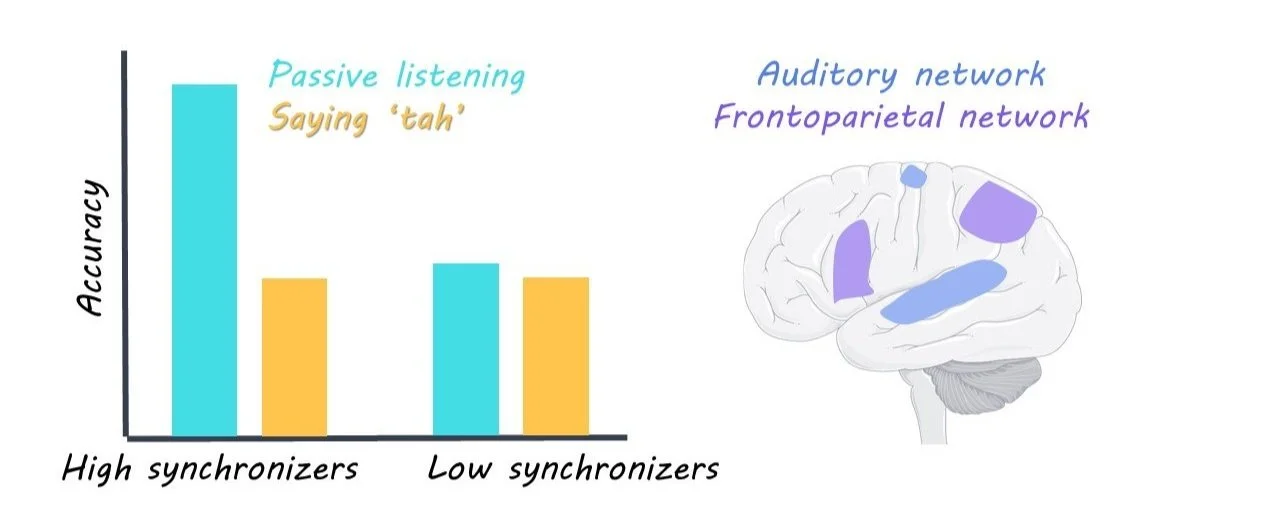
Synchronizers did better at the statistical learning task, but only if they were allowed to listen passively. When they had to say “tah” while listening, their performance decreased to the level of the non-synchronizers. Non-synchronizers did equally well whether they were saying “tah” or passively listening.
MRI revealed that synchronizers were recruiting an additional brain network to process speech during statistical learning. While non-synchronizers only used the auditory network, synchronizers also used a fronto-parietal network, which is composed of some regions in the frontal lobe and others in the parietal lobe. Previous research identifies the fronto-parietal network as being involved in salience, attention, or monitoring.
What's the impact?
This study highlights some important individual differences in language processing. Research into spontaneous synchronization and the fronto-parietal network’s role in speech might shed some light on normal and abnormal language development.